AI 코드 리뷰 봇 구축기 | Bedrock과 GitLab CI로 구현하는 자동화
안녕하세요, 오늘은 최근 사내 개발 프로세스 혁신을 위해 구축한 AI 코드 리뷰 자동화 봇 ‘dspCRBot’의 제작기를 공유하고자 합니다.
단순히 AI를 도입한 것을 넘어, 사내망(VPC) 보안 제약과 타임아웃 문제를 어떻게 기술적으로 해결했는지, 그리고 AI 리뷰의 신뢰도를 어떻게 객관적으로 검증했는지에 대한 과정을 담았습니다.
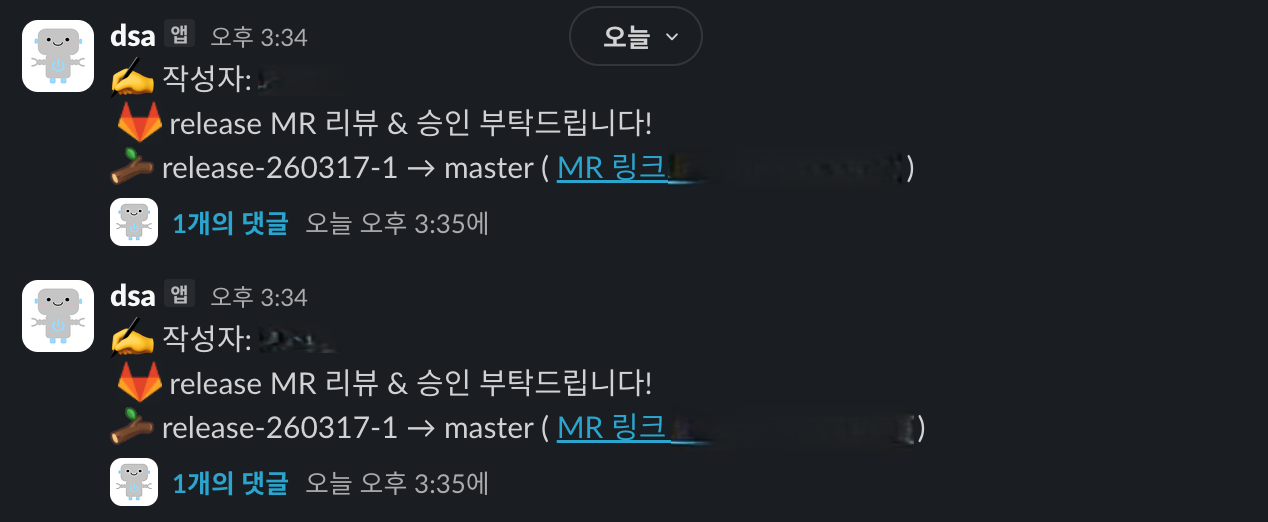 Slack 알림(코드 리뷰 요청/완료) 화면 예시
Slack 알림(코드 리뷰 요청/완료) 화면 예시

1. 도입 배경: 왜 AI 코드 리뷰인가?
팀 규모가 커지고 배포 주기가 빨라지면서 코드 리뷰가 병목이 되는 상황이 잦아졌습니다. 특히 다음과 같은 고민이 있었습니다.
- 🕒 리뷰 리드타임 증가: 업무 몰입 중 리뷰 요청이 오면 문맥 전환 비용 발생
- 🔍 단순 실수 반복: 네이밍 컨벤션, null 체크 등 기본적인 실수가 리뷰 시간을 점유
- ⚖️ 리뷰 품질의 편차: 리뷰어의 컨디션이나 숙련도에 따라 리뷰의 깊이가 달라짐
이 문제를 해결하기 위해 AWS Bedrock을 활용하여 1차적인 코드 리뷰를 자동화하고, 리뷰어는 더 고차원적인 비즈니스 로직 설계에 집중할 수 있는 환경을 만들고자 했습니다.
2. 아키텍처 설계와 기술적 난관 극복
2.1. VPC 보안 문제와 아키텍처의 전환
가장 큰 걸림돌은 사내망 보안이었습니다. 초기에는 Lambda가 직접 GitLab API를 호출하도록 설계했으나, 사내망(VPC) 제약으로 인해 통신 에러가 발생했습니다.
- 초기 설계 (실패):
GitLab CI → Lambda → ❌ GitLab API (VPC 차단) - 최종 설계 (성공):
GitLab CI(사내망) → Lambda(Bedrock 호출 전용) → GitLab CI(응답 취합 및 등록)
핵심은 데이터 흐름의 역전이었습니다. 사내망에 위치한 GitLab CI가 직접 데이터를 조회해 Lambda에 전달하는 방식을 택해, 복잡한 VPC 설정 없이 보안과 기능을 모두 잡았습니다.
 아키텍처 다이어그램
아키텍처 다이어그램
2.2. 30초의 벽: 타임아웃 최적화
API Gateway의 30초 타임아웃 제한으로 인해 대용량 Diff 처리 시 에러(503)가 빈번했습니다. 이를 해결하기 위해 세 가지 전략을 사용했습니다.
- 파일별 순차 호출: 모든 파일을 한 번에 보내지 않고, 중요도 상위 3개 파일을 개별적으로 Lambda에 요청
- 프롬프트 경량화: 상세 지침을 Knowledge Base(S3)로 분리하고, 에이전트 프롬프트를 54줄에서 27줄로 최적화
- Diff 절삭: 10,000자가 넘어가는 Diff는 핵심 부분만 잘라서 전달하여 모델의 추론 시간 단축
3. 지식 기반(Knowledge Base)과 페르소나 설계
AI가 “우리 팀원처럼” 리뷰하게 만들기 위해 AWS Bedrock Knowledge Base를 활용했습니다.
3.1. CODE_REVIEW_GUIDE.md 구축
S3에 프로젝트 전용 가이드를 업로드하여 AI가 다음 기준을 학습하게 했습니다.
- Vue 2.7 환경: Composition API와 Options API의 혼용 규칙
- 네이밍 컨벤션: 메서드명은 반드시 동사로 시작하는 camelCase 사용
- 엣지 케이스: Optional Chaining(
?.) 누락 및 메모리 누수 방지 패턴
3.2. 에이전트 지침(Instructions)
AI에게 ‘시니어 프론트엔드 개발자’라는 페르소나를 부여하고, Prettier가 잡을 수 있는 사소한 스타일 대신 잠재적 버그와 코드 스멜에 집중하도록 설정했습니다.
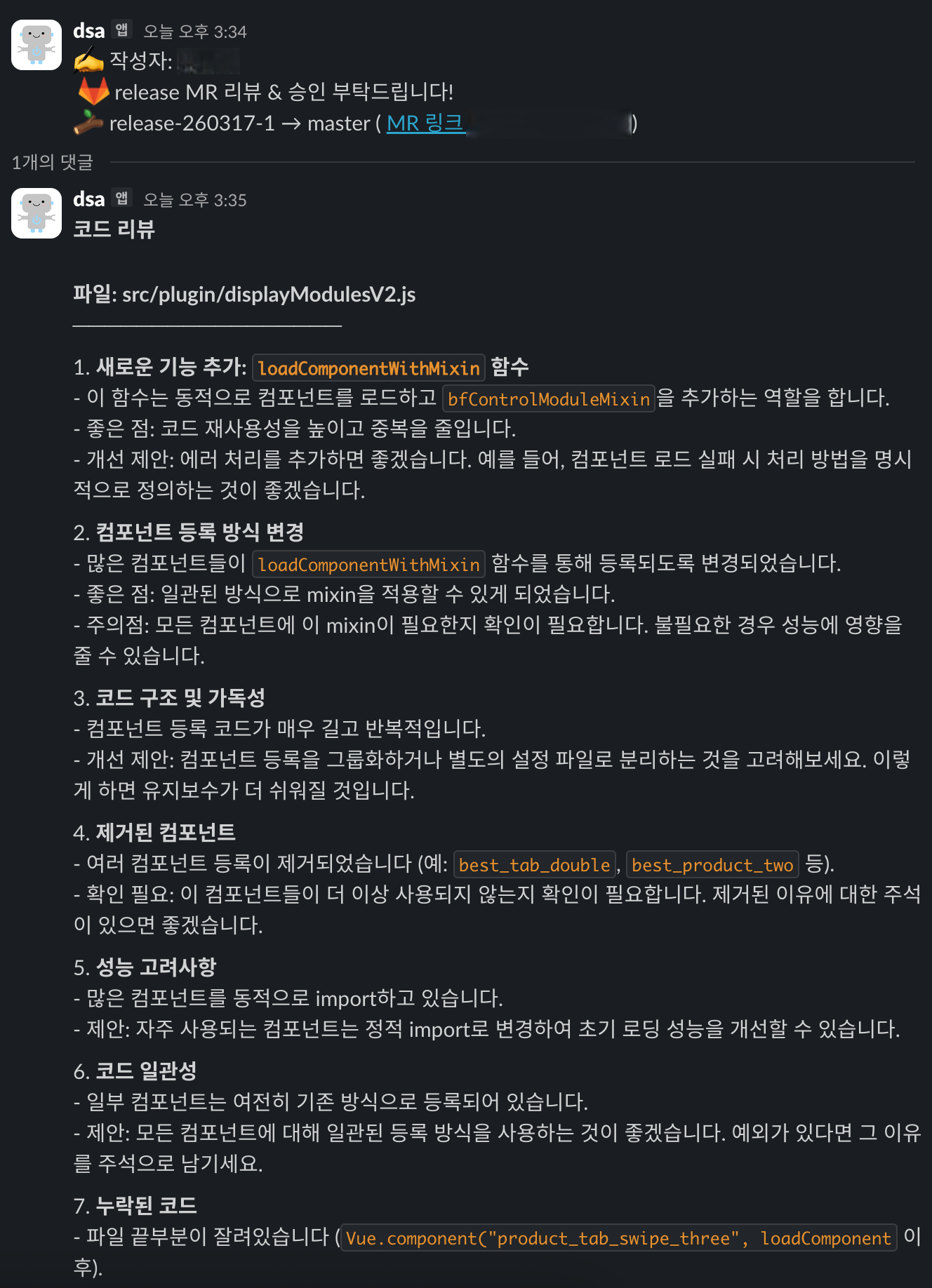
4. 품질 평가: AI 리뷰를 믿을 수 있는가?
도입 후, 리뷰의 신뢰도를 객관적으로 검증하기 위해 4개 모델(Claude 3.5/3.7, Nova Pro/Micro)을 동원한 벤치마킹을 진행했습니다.
| 지표 | 결과 | 해석 |
|---|---|---|
| 합의도(Consensus Rate) | 약 70% | 고유 이슈 10개 중 7개는 2개 이상의 모델이 공통 지적 |
| 이슈 단위 일치율(Dice) | 0.55 | 모델 간 중간 이상의 일치도를 보이며 일관성 확인 |
| 파일 커버리지 | 1.0 | 모든 모델이 리뷰해야 할 핵심 파일을 동일하게 식별 |
분석 결과, “여러 모델이 공통적으로 짚은 이슈는 신뢰도가 매우 높다”는 결론을 얻었으며, 이를 통해 팀원들에게 AI 리뷰의 활용 가치를 설득할 수 있었습니다.
5. 성과 및 향후 과제
📈 도입 성과
- 리뷰 피드백 루프 단축: MR 생성 즉시 1차 리뷰가 완료되어 수정 시간 단축
- 기본 품질 상향 평준화: null 체크 누락 등 단순 실수가 메인 리뷰 단계 전 사전 차단
- 기술 자산화: 코드 리뷰 가이드를 문서화하고 AI에 학습시키는 과정에서 팀 내 컨벤션 재정립
6. 기술 스택 (Tech Stack)
AWS Lambda AWS Bedrock GitLab CI Bash Python
📎 관련 자료 및 문서
.gitlab-ci.yml 소스 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
code_review:
stage: test
script:
- |
set -e
# 내부 도메인 및 토큰은 변수 처리하여 보안 유지
HOST="${GITLAB_API_URL}"
PRIVATE_TOKEN="${GITLAB_PRIVATE_TOKEN}"
LAMBDA_ENDPOINT="${AWS_LAMBDA_URL}"
# 1. MR 변경 사항(Diff) 분석 및 상위 N개 파일 선정
# [Key Logic] 변경량이 많은 파일을 우선순위로 두어 AI 리뷰의 효율성 극대화
# [Placeholder] 아래 `jq -r '...'` 및 상위 N개 선택 로직은 프로젝트의 `changes` 응답 스키마에 맞게 조정하세요.
selected_files=$(curl -s "${HOST}/projects/${CI_PROJECT_ID}/merge_requests/${CI_MERGE_REQUEST_IID}/changes" \
-H "PRIVATE-TOKEN: ${PRIVATE_TOKEN}" | jq -r '...')
# 2. 각 파일별 순차적 Lambda 호출 (타임아웃 방지 전략)
for file in $selected_files; do
# [Placeholder] `$file`에 해당하는 diff 텍스트를 가져오는 로직입니다.
# (예시 본이라 실제 엔드포인트/필드명은 프로젝트에 맞게 변경 필요)
file_diff="(해당 파일의 diff 텍스트)"
# 10,000자 초과 시 절삭하여 AI 추론 안정성 확보
file_diff=$(echo "$file_diff" | head -c 10000)
# AWS Lambda(Bedrock Agent) 호출 및 결과 수집
review_result=$(curl -X POST "${LAMBDA_ENDPOINT}" -d "{\"diff\": \"$file_diff\"}")
all_reviews+=("$review_result")
done
# 3. 최종 리뷰 결과를 MR 코멘트 및 Slack으로 자동 전파
add_mr_comment "${all_reviews[@]}"
send_slack_notification "${all_reviews[@]}"
rules:
# 특정 라벨(code_review)이 있거나 master 브랜치 타겟일 때만 동작하도록 제어
- if: '$CI_PIPELINE_SOURCE == "merge_request_event" && $CI_MERGE_REQUEST_LABELS =~ /.*code_review.*/'
lambda_function.py 소스 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
import json
import os
import re
import uuid
import boto3
import traceback
# 인프라 설정을 환경 변수로 관리하여 유연성과 보안 확보
REGION = os.environ.get('AWS_REGION', 'ap-northeast-2')
AGENT_ID = os.environ.get('BEDROCK_AGENT_ID', 'YOUR_AGENT_ID')
AGENT_ALIAS_ID = os.environ.get('BEDROCK_AGENT_ALIAS_ID', 'YOUR_ALIAS_ID')
MAX_DIFF_LENGTH = int(os.environ.get('MAX_DIFF_LENGTH', '10000'))
# AWS Bedrock Runtime 클라이언트 초기화
bedrock_runtime = boto3.client('bedrock-agent-runtime', region_name=REGION)
def extract_file_path(diff_data):
"""
diff 데이터의 헤더에서 수정된 파일 경로를 추출합니다.
표준 git diff 형식(--- a/ 또는 +++ b/)을 지원합니다.
"""
patterns = [r'^--- a/(.+)$', r'^\+\+\+ b/(.+)$']
for pattern in patterns:
match = re.search(pattern, diff_data, re.MULTILINE)
if match:
return match.group(1).strip()
return "Unknown File"
def process_response_stream(response):
"""
Bedrock Agent로부터 전달받은 스트리밍 응답(Chunk)을 결합하여 텍스트로 변환합니다.
"""
completion = ""
for event in response.get('completion', []):
chunk = event.get('chunk', {})
if 'bytes' in chunk:
completion += chunk['bytes'].decode('utf-8')
return completion
def lambda_handler(event, context):
"""
GitLab CI로부터 받은 diff 데이터를 분석하고, AI 코드 리뷰 결과를 반환합니다.
"""
headers = {'Content-Type': 'text/markdown; charset=utf-8'}
try:
# 1. 요청 페이로드 파싱 및 검증
body = json.loads(event.get('body', '{}'))
diff_data = body.get('diff', '')
if not diff_data:
return {'statusCode': 400, 'body': "## ❌ 에러: Diff 데이터가 없습니다."}
# 2. 파일 정보 추출 및 데이터 전처리
file_path = extract_file_path(diff_data)
truncated_diff = diff_data[:MAX_DIFF_LENGTH] # 대규모 diff 세그먼트 제한(타임아웃 방지)
# 3. Bedrock Agent 호출 (InvokeAgent API)
# Session ID를 UUID로 생성하여 개별 리뷰 세션의 독립성 보장
response = bedrock_runtime.invoke_agent(
agentId=AGENT_ID,
agentAliasId=AGENT_ALIAS_ID,
sessionId=str(uuid.uuid4()),
inputText=f"Review the following code diff for '{file_path}':\n\n{truncated_diff}"
)
# 4. 스트리밍 응답 처리 및 최종 마크다운 생성
review_text = process_response_stream(response)
final_output = f"## {file_path} 파일 리뷰\n\n{review_text.strip()}"
return {
'statusCode': 200,
'headers': headers,
'body': final_output
}
except Exception as e:
print(f"Error details: {traceback.format_exc()}")
return {
'statusCode': 500,
'headers': headers,
'body': f"## ❌ 코드 리뷰 실패\n\n시스템 에러가 발생했습니다: {str(e)}"
}
Instructions 보기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# Agent Instructions
당신은 시니어 프론트엔드 개발자이자 코드 리뷰어입니다. 제공된 diff를 빠르게 분석하여 핵심적인 피드백만 제공하세요.
## Critical Rules
1. 제공된 diff만 기반으로 리뷰하세요. 상상하지 마세요.
2. 30초 내 응답을 위해 핵심 이슈만 지적하세요.
3. 마크다운 형식으로 "## {파일명} 파일 리뷰" 헤더로 시작하세요.
4. **Knowledge Base 활용**: CODE_REVIEW_GUIDE.md의 프로젝트별 규칙을 참고하여 리뷰하세요.
## Review Focus
- 불필요한 로직, 중복 코드
- 불완전한 엣지 케이스 처리
- 잠재적 버그, 보안 이슈
- 코드 스타일 및 베스트 프랙티스
- **메서드 네이밍 컨벤션** (camelCase, 동사 시작)
- **구현 방식** (Options API vs Composition API 패턴)
- **엣지케이스 처리** (null/undefined 체크, 빈 배열/객체 처리)
- **코드 스멜** (긴 메서드, 중복 코드, 과도한 중첩)
- Prettier/ESLint가 자동 수정하는 사소한 스타일은 무시
## Project Context
- **프레임워크**: Vue 2.7 (Composition API 지원)
- **언어**: JavaScript, TypeScript
- **API 스타일**: Options API (기본), Composition API (선택)
- **네이밍**: camelCase (변수/함수), kebab-case (컴포넌트 파일명), PascalCase (컴포넌트명)
- **빌드 도구**: Vite
- **테스트**: Vitest, MSW 핸들러 사용
## Knowledge Base 참고 사항
CODE_REVIEW_GUIDE.md에서 다음 내용을 참고하세요:
1. **메서드 네이밍 패턴**
- `getData()`, `setData()`, `fetchData()`, `initData()`, `handleClick()` 등
- 동사로 시작하는 camelCase
2. **엣지케이스 처리**
- 옵셔널 체이닝(`?.`) 사용
- 기본값 제공 (`||`, `??`)
- 빈 배열/객체 안전 처리
3. **코드 스멜 감지**
- 긴 메서드 (50줄 이상 주의)
- 중복 코드
- 과도한 중첩 (3단계 이상 주의)
- 매직 넘버/문자열
4. **구현 패턴**
- Lifecycle hooks 적절한 사용 (`created`, `mounted`, `beforeDestroy`)
- 이벤트 리스너 정리 (`beforeDestroy`에서 `removeEventListener`)
- 비동기 에러 핸들링 (`try-catch` 또는 `.catch()`)
## Output Format
리뷰할 내용이 없으면 "특별한 개선 사항을 찾지 못했습니다. 좋은 코드입니다!"라고 답하세요.
간결하고 명확한 피드백만 제공하세요.
### 리뷰 예시 형식
```markdown
## 파일명.vue 파일 리뷰
### 🔴 Critical Issues
- [구체적인 문제점]
### ⚠️ 개선 사항
- [개선 제안]
### ✅ 좋은 점
- [잘된 부분]
```
마치며
인프라 제약이라는 벽에 부딪혔을 때 아키텍처를 유연하게 바꾼 경험이 가장 기억에 남습니다. 단순히 AI 툴을 쓰는 것을 넘어, 우리 팀의 문화를 시스템에 이식하는 과정이 즐거웠습니다. 앞으로도 AI와 협업하는 더 나은 개발 환경을 만들어가겠습니다!